sdk0002
のバックアップ(No.4)
[
トップ
|
一覧
|
単語検索
|
最終更新
|
バックアップ
|
ヘルプ
]
バックアップ一覧
差分
を表示
現在との差分
を表示
ソース
を表示
sdk0002
へ行く。
1 (2019-04-02 (火) 17:21:32)
2 (2019-04-02 (火) 17:37:11)
3 (2019-04-02 (火) 20:27:23)
4 (2019-04-03 (水) 09:39:54)
5 (2019-04-03 (水) 12:11:00)
6 (2019-04-03 (水) 15:23:56)
7 (2019-04-04 (木) 07:11:02)
川合秀実の数独研究に関するドキュメント#2
(by
K
, 2019.04.02)
↑
(4) 富士型 (2015年07月ごろ)
そうこうしているうちに大した成果も出ないまま、2年が過ぎていました。
私の仮説として、難問は何らかのパターンを有しているというのがあります。・・・つまりこういうことです。高得点の難問を集めてじっと見つめていると、共通のパターンが見えてきて、そのパターンを見出した後は、そのパターンを有する問題を大量生産してgsf's -q2 ratingをひたすら計算すれば、きっと未知の超絶難問を見つけることができるだろう、ということです。
要するに「既知の難問に似た問題を作りまくっていれば、そのうち何とかなるでしょう、・・・何とかなったらいいな、・・・何とかなってくれ!」という安直なアイデアです(笑)。
いやだって、もう自分たちの計算力を考えたら、全探索なんて全く望めないわけで、そうなれば「(正解が)ありそうなところを必死で探す」しか戦略はないわけです。
ということで「富士型」は
#06: 000100020000030400005006007400000000086007000709000005000400300000020010060008009 q2=99480
に類似の問題を探すために見いだされたパターンです。
富士型がどういう形なのか当初はわかっていなかったのですが、研究が進むにつれて簡潔に表せるようになってきました。ここでは簡潔に紹介します。
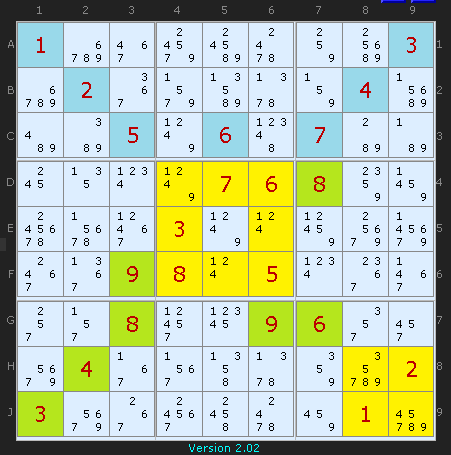
この図は、q2=99480の問題を同値変形(後述)して、
http://www.sudokuwiki.org/sudoku.htm
に入力して見やすくしたものです。
この中で数字の背景が青のものは、位置だけではなく数字の値もこの値に固定できます。
緑の背景は、位置は固定ですが、数字の値は問題によって変わる部分です。
黄色の部分は、位置も値も変わる部分です。
なぜこのパターンに注目したかですが、
まずA〜C行を3行まとめた「ボックス行」(勝手に命名)に注目してください。この中にあるヒント数字は、7つあります。・・・これは同様に、D〜Fのボックス行やG〜Jのボックス行に当てはまります。さらに、1〜3列をまとめたボックス列、4〜6列をまとめたボックス列、7〜9列をまとめたボックス列についても、ヒント数字はきっかり7つです。
したがって自動的にこの数独問題の総ヒント数は21になるわけですが、だからこの数独問題は
どのボックス行・列にも均等にヒントが配されている
ことになります。
また中央のヒントを5つ含んでいるボックスはちょっと特別なので除外して、それを含まない4本のボックス行・列については、7つのヒント数字は全く重複がありません。
また使われているヒント数字の出現回数ですが、2〜3回になっています。これは、9種類の数字があって数字は全部で21回出さなければいけないとすると、均等な出現回数を目指せば同じ数字は2〜3回出るしかないわけですが、まったくその通りになっているのです。
おおなんと美しい!・・・美しいといえば富士山ですよね、だから富士型と命名しました。
私はq2ランキングの上位問題をぼんやり眺めていて、ヒント数=21の問題に注目してみたら、いくつかがこの「どのボックス行・列にも均等にヒントが配されている、かつボックスごとのヒント数は、5個ボックスx1,3個ボックスx4,1個ボックスx4になっている」パターンがあることに気付き、それを同値変形しまくって、上図の一般化に成功したのでした。
さてここまで限定できれば、あとは総当たりで問題を作ってq2のratingを計算するだけです。・・・結果は・・・結局、99480を超えることはできませんでした。つまり富士型の最高得点は、#06の問題で、既出だったのです。
しかし富士型に関する研究は、私たちを大いに盛り上げました(特に私が盛り上がりました)。パターンを見出して探しまくるという手法が一通りやれたわけです。・・・何よりまずパターンを見つけたときに、ものすごく盛り上がります。これはいける!と思うわけです。そして探索プログラムを走らせて、次こそは未知の超難問が出力されるんじゃないかと、すごくわくわくするわけです。・・・そしてそんなものが出てこないと判明すると「ああ、このパターンはすでに掘りつくされていたのか・・・」と思うわけです。
この富士型の探索も含めて、一般に私の探索のやり方の場合、コンピュータの処理時間の大半は「解の一意性判定」になります。これは自分の決めたパターンに数字を配してみても、それだけでは数独の問題として成立しているとは限らないので、解はあるのか、解があったとしてもその解はちゃんと一つだけになっているのか、を確認しなければいけないのです。これが探索処理全体としては一番CPU時間がかかるのです。
最初はパターンなんかに頼らず、まず数独の解(81マスがすべて埋まったもの)を用意して、そこから数字を抜いて作問する方式なら、少なくとも解が0個になる心配はありません。そうすると高速化できそうなのですが、その場合はパターンを満たしていない数独問題がいくつもできてそれを捨てなければいけなくて、むしろ遅くなってしまうので、私のやり方には使えないのです。
↑
(5) 数独の同値変形について
↑
(6)
![[K Wiki]](k.jpg "[K Wiki]")